Curvine 元数据架构说明
元数据是分布式文件系统的核心组件,相当于系统的“导航中枢”,主要负责管理文件/目录的命名空间、存储位置、大小权限、修改时间等关键信息,其读写速度、存储容量和数据一致性,直接决定了整个分布式文件系统的运行性能、稳定性和可用性。Curvine 结合分布式存储领域的最佳实践,经过多方案对比验证,最终选用「Raft 协议 + RocksDB 数据库」的核心组合来管理元数据,既能满足高并发场景下的低延迟需求,又能支撑海量元数据存储,同时保障多节点数据一致,以下是简化且完整的核心说明。
1. 设计目标与选型
Curvine 元数据架构的核心设计目标的明确且聚焦,主要围绕四大核心需求展开:一是支持千万至百亿级文件/目录的元数据存储,适配海量小文件、大文件混合的存储场景;二是保障高并发读写场景下的低延迟,应对频繁的文件创建、删除、修改等高频操作;三是实现分布式集群多节点数据一致,避免出现“本地修改后其他节点不可见”的问题;四是兼顾运维便捷性与成本可控,降低部署、监控和故障恢复的复杂度。
在选型过程中,技术团队对比了 HDFS NameNode、TiDB、Redis 及独立 Raft 集群等多种主流方案,最终确定「Raft + RocksDB」的组合架构,核心考量有三点:其一,二者均经过大规模生产场景验证,工程成熟度高,稳定性有保障,广泛应用于各类分布式存储系统;其二,RocksDB 基于 LSM-Tree 架构,具备高并发写入、高压缩比、海量存储的优势,非常适合存储元数据这类高频读写、海量小条目数据;其三,Raft 协议能高效解决分布式集群的一致性问题,通过简单清晰的机制实现多节点数据同步,避免单点故障,兼顾一致性与性能。
为了实现“速度、存储、一致性”三者平衡,架构采用「三层分工」模式,各层各司其职、协同配合,具体分工如下:
| 层次 | 核心职责 | 设计动机 |
|---|---|---|
| 内存目录树 | 专门处理路径解析、目录列举、文件夹关联等高频操作,仅存储目录核心结构信息(文件夹名称、父文件夹关联关系) | 内存读写速度远快于磁盘,将高频操作的核心信息放在内存中,可将目录查询、路径匹配等操作延迟控制在微秒级;同时仅维护轻量目录结构,大幅降低内存占用,避免内存资源浪费。 |
| 元数据 RocksDB(Inode 引擎) | 持久化存储所有文件/目录的完整详细信息,包括文件大小、权限、修改时间、数据块位置,以及目录关联的完整关系等 | 承接海量元数据的持久化存储需求,通过「列族」机制将不同类型的元数据分类存储(如文件属性、目录关系分开管理),提升读写效率和管理便捷性,同时适配高频元数据修改场景。 |
| Raft 日志 RocksDB | 专门存储所有元数据修改操作的日志(创建、删除、修改等),按操作顺序记录,用于多节点同步 | 与业务元数据存储完全隔离,避免日志存储与业务读写相互影响,同时便于日志的同步、压缩、清理和故障恢复,减少性能损耗。 |
内存目录树和 RocksDB 并非独立运行,而是形成“内存管快、磁盘管存”的协同模式,既保证高频操作的速度,又实现海量数据的存储,核心协同逻辑如下:
内存目录树:聚焦高频操作的极致速度,仅存储目录最核心的结构信息(文件夹名称、父文件夹ID、子节点列表),不存储文件的详细属性(如大小、修改时间)。这样设计既能将内存占用控制在极低水平,又能让列目录、找文件路径等高频操作在内存中直接完成,响应速度极快。
RocksDB:聚焦海量数据的可靠存储,承载所有文件/目录的完整详细信息,包括文件大小、权限、修改时间、数据块在磁盘中的位置等。通过列族分类管理不同类型的元数据,让数据组织更清晰,同时利用自身高并发读写特性,确保海量元数据的读写效率。
协同逻辑:采用“按需加载、分工响应”的方式。例如,当用户列某个目录的内容时,内存目录树先快速返回该目录下所有文件/文件夹的名称,确保响应速度;当用户需要查看某个文件的详细信息(如大小、修改时间)时,系统再去 RocksDB 中批量查询对应的详细信息,一次性返回,既保证了速度,又不浪费内存资源。
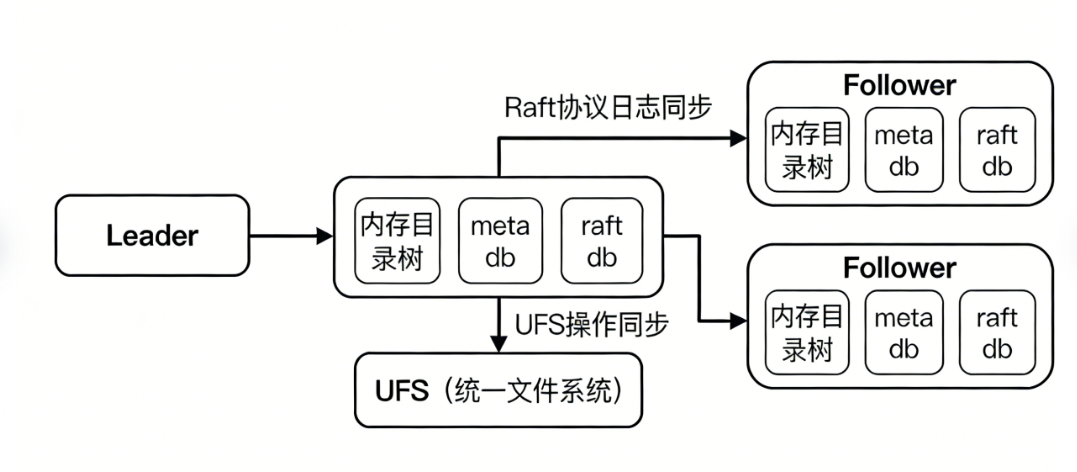
3. Raft 协议:保障多节点数据一致的核心机制
分布式集群的核心痛点是“数据不一致”——比如在一台机器上创建文件,另一台机器却无法查看,影响业务正常运行。Raft 协议作为 Curvine 分布式集群的“一致性中枢”,专门解决这一问题,核心机制简单且高效:
日志同步优先:任何元数据修改操作(创建、删除、重命名、修改属性等),都会先被封装为一条操作日志,存入专门的日志数据库,然后同步到集群中超过半数的机器上。只有多数机器都成功接收并存储这条日志,本次修改操作才算正式生效,确保数据不会因单台机器故障而丢失。
日志回放保一致:集群中的 Leader 节点负责发起修改操作、记录日志,Follower 节点(从节点)会实时同步 Leader 的日志,然后按照日志的顺序,逐一条执行相同的修改操作,确保所有节点的元数据状态完全一致,避免出现数据偏差。
快照加速恢复:如果某台机器因故障、断网等原因,落后 Leader 节点过多日志,无需逐一条回放所有历史日志,Leader 会直接发送当前数据的完整快照,该机器加载快照后就能快速追上集群进度,大幅缩短故障恢复时间,提升系统可用性。
4. Leader 优先写:兼顾速度与一致性的巧妙权衡
为了适配高并发、低延迟的业务场景,Curvine 对传统 Raft 协议的执行流程做了合理优化,采用“Leader 优先写”的策略,区别于传统“先同步日志、再改本地数据”的模式:
核心流程:Leader 节点先更新自身的内存目录树 → 写入本地 RocksDB 完成本地数据修改 → 再将本次修改的日志同步给集群中的其他 Follower 节点,完成一致性同步。
核心优势:写入速度大幅提升。无需等待日志同步到多数机器再完成本地修改,本地写入延迟可降低至几毫秒,高并发场景下(如大量小文件创建),吞吐量能提升数倍,完美适配高频小操作场景。
微小代价:极短的一致性窗口。如果 Leader 节点刚完成本地修改,还未同步日志就发生故障,这部分未同步的修改可能无法同步到其他节点,但这个窗口极短(通常仅几毫秒),实际生产中出现的概率极低,是性能与一致性之间可接受的权衡。
5. 日志批处理优化:进一步提升高并发吞吐量
针对大量小文件创建、修改等高频小操作场景,Curvine 引入日志批处理机制,进一步提升写入吞吐量,避免频繁同步日志带来的性能损耗:
核心逻辑是“攒一批、再同步”:系统会将短时间内(通常 1-10 毫秒)或一定数量(如 100 条)的元数据修改操作,合并为一个批量日志,再同步到集群其他节点。这样做的核心好处是减少日志同步的次数,降低网络传输和磁盘写入的开销,高并发场景下吞吐量可提升数倍。
同时,批处理参数可灵活调整,可根据业务需求设置批处理的时间窗口(如 1 毫秒、5 毫秒)和批量条数(如 50 条、100 条),在写入延迟和吞吐量之间找到最优平衡——窗口越短,延迟越低;批量越大,吞吐量越高。此外,由于 Raft 日志已能保障数据一致性,RocksDB 自身的 WAL 日志是关闭的,进一步提升写入速度。
6. 选型取舍:为何不采用 TiDB、Redis 等外部数据库
在元数据存储方案选型时,技术团队也重点评估了 TiDB、Redis 等成熟外部数据库,但最终选择自研“内存目录树 + RocksDB + 内置 Raft”的架构,核心原因是外部数据库无法适配 Curvine 高并发、低延迟的核心需求,具体取舍如下:
延迟过高:外部数据库需要通过网络通信完成读写,每次元数据操作都要多走一次网络,尾延迟会显著升高,远不如“内存+本地 RocksDB”的本地操作速度快,无法满足高频小操作的低延迟需求。
易出现性能瓶颈:元数据操作多为高频小请求,海量客户端同时连接外部数据库时,很容易打满数据库连接数,导致 QPS 触顶,无法支撑高并发场景。
运维成本高且繁琐:引入外部数据库会增加集群的依赖组件,需要额外部署、监控、维护这套数据库,故障恢复也更复杂;同时,随着元数据量增长,外部托管数据库的成本会大幅上升,不符合成本可控的目标。
优化空间有限:外部数据库是通用型设计,无法针对元数据的高频目录操作、批量读写等特点做定制化优化,而自研架构可深度优化路径解析、按需加载等核心流程,更贴合业务需求。
7. fs-mode 模式:与 UFS 协同,保障数据兜底安全
Curvine 支持 fs-mode 模式,核心作用是将元数据和文件数据同步到底层统一文件系统(UFS),形成“本地存储+磁盘兜底”的双重保障,避免数据丢失,同时不影响系统性能:
元数据镜像同步:Curvine 中的所有元数据修改(创建、删除、修改属性),都会在本地完成后,后台异步同步一份到 UFS,确保 Curvine 与 UFS 的目录结构、文件属性完全一致,实现统一命名空间。
数据异步拷贝:文件的实际数据块,会在后台异步从 Curvine 拷贝到 UFS,拷贝过程不影响本地元数据的读写操作,避免拖慢写入速度;若 UFS 暂时不可用,拷贝任务会自动重试,直到同步成功。
幂等重试保障:同步操作采用幂等设计,同一个修改操作重复执行,结果也不会发生变化,避免出现重复创建文件、重复删除等异常,确保同步过程的可靠性。
进度跟踪与快速恢复:系统会分别记录“Curvine 本地最新修改进度”和“UFS 同步进度”,若 UFS 因故障、断网落后过多,恢复后无需重新同步所有数据,只需从上次中断的进度继续同步,大幅提升恢复效率。
8. 架构小结
Curvine 元数据架构的核心逻辑,可概括为“三层分工、一个权衡、一个兜底”,既保证了速度和海量存储,又兼顾了数据一致性和运维便捷性:
三层分工:内存目录树管速度(高频操作秒响应),RocksDB 管存储(海量元数据稳承载),Raft 协议管一致(多节点数据无偏差),三者协同,实现“快而稳、省而全”;
一个权衡:采用 Leader 优先写策略,以极短的一致性窗口,换取高并发场景下的低延迟和高吞吐量,适配大量小文件读写的核心场景;
一个兜底:通过 fs-mode 模式与 UFS 协同,实现元数据和文件数据的双重备份,保障数据安全,同时支持快速故障恢复;
选型优势:放弃外部数据库,采用本地架构,既降低了延迟和运维成本,又保留了定制化优化空间,完美适配分布式文件系统的核心需求。