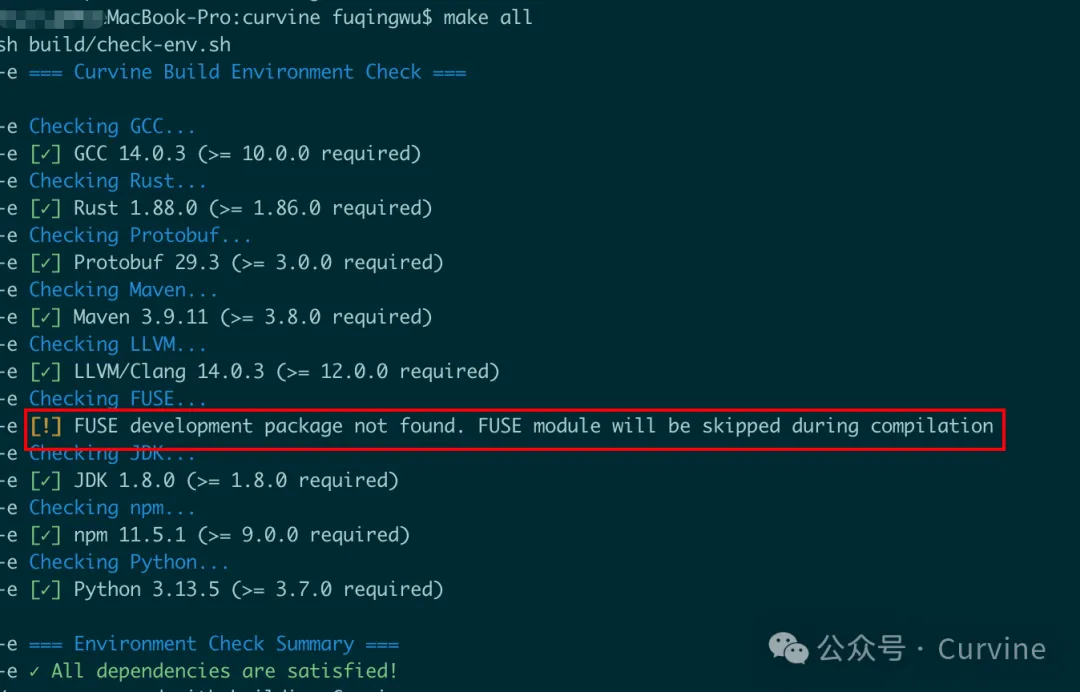
AI Agent 存储选型:Curvine 如何在 EKS 上支撑万级Agent运行
一、AI Agent 大规模部署的存储难题
2026 年的 AI 基础设施正在经历一个根本性的架构转变:从"一个大模型实例服务所有请求"的中心化模式,走向"成千上万个 Agent 实例各自独立运行"的分布式模式。
这不是概念上的变化。以使用 Vite 进行前端开发为例:Agent 在 debug 阶段需要运行 Vite 这类构建工具,Vite 的 dev server 依赖对项目 node_modules 和源码目录的高速随机读取来实现按需编译和模块热更新(HMR),开发者每次保存文件后期望在毫秒级看到页面变化,这对底层文件系统的小文件随机读性能和 inotify/fswatch 事件通知延迟都有很高要求。如果存储层跟不上,整个开发体验就会变得卡顿。
每一个 Agent 实例都不是无状态的 HTTP handler,而是一个有独立工作目录、需要持久化存储的有状态进程。以 OpenClaw 这类 Agent 平台为例,OpenClaw 的整个记忆和协作系统建立在文件之上:SOUL.md 定义 Agent 的人格与行为边界,AGENTS.md 描述行为规则与会话工作流,MEMORY.md 存储跨会话的长期记忆,此外还有 USER.md、TOOLS.md、HEARTBEAT.md 等一组在启动时自动加载的 Markdown 文件,再加上项目源码、node_modules、.git 历史等。每个 Agent 实例运行在独立沙箱中,这些文件随时被读写和更新。当平台同时为数千个开发者分配各自的 Agent 实例时,就是典型的"万级独立文件系统"需求:每个实例需要隔离的 POSIX 工作空间,文件数量密集,且读写频繁。
从 Kubernetes 的视角来看,这意味着你的集群需要同时支撑数千甚至上万个独立的 PersistentVolumeClaim。每个 PVC 都要能快速 provision,Agent 弹性扩缩容时不能等几分钟才拿到存储,同时要有低延迟的文件 I/O,并且在 Pod 被调度到其他节点后数据依然可达。
这种"海量小规模有状态实例"的负载模式,和传统的数据库、消息队列等有状态应用完全不同。后者通常是少数几个大 PVC,前者是上万个小 PVC。亚马逊云科技原生的存储服务在面对这种新模式时,各自存在不同的优劣势。
1.1 Amazon EBS:隔离性好,但挂载数是硬限制
EBS 的优势在于隔离性。每个 Agent 一个独立的 EBS volume,性能互不干扰,故障也不会互相传染。对于需要严格租户隔离的场景,这是最干净的方案。
但问题是:单个 EC2 实例能挂载的 EBS volume 数量有硬性上限。对于大部分 Nitro 实例(包括本次测试使用的 r6g 系列),最大 attachment 数为 28,这个数字还要和网络接口、NVMe instance store 共享。扣除主网卡后,实际可挂载的 EBS volume 大约在 27 个左右。第 7 代以后的部分实例类型(如 M7i、R7i 等)引入了独立的 EBS volume limit,根据实例大小不同有更高的配额,但对于 r6g 这类仍在 shared limit 下的实例,28 就是天花板。(参考:Amazon EBS volume limits for Amazon EC2 instances)
这意味着什么?在我们的测试场景中,每台 r6g.4xlarge 节点跑了约 100 个 Agent Pod。如果用 EBS 给每个 Pod 分配独立 volume,一台节点最多挂 28 个,你需要将近 4 倍的节点数量才能承载相同的 Pod 密度,计算资源利用率直接从 88% 掉到 20% 左右。
此外,EBS volume 绑定单个 AZ,无法跨 AZ 使用。一旦 Pod 被调度到其他 AZ 的节点上,原有的 EBS volume 就不可达,只能限制 Pod 调度到特定 AZ。对于需要跨 AZ 高可用和快速弹性伸缩的 Agent 平台来说,这是一个架构层面的硬约束。
1.2 Amazon EFS:隔离机制成熟,但大规模 provision 是瓶颈
EFS 作为托管的 NFS 文件系统,配合 Access Point 可以为每个 Agent 分配隔离的目录视图。每个 Access Point 有独立的 POSIX 权限和根目录,做到了文件系统级别的租户隔离。而且 EFS 支持 ReadWriteMany,Pod 跨节点调度后无需 detach/attach 操作,从调度灵活性的角度看很理想。自 2025 年 2 月起,单个 EFS 文件系统最多支持 10,000 个 Access Point,从配额上看足以覆盖万级 Agent 场景。
然而在实际大规模部署中,瓶颈出现在 provision 速度上。当你通过 EFS CSI Driver 的动态 provisioning 同时创建数千个 PVC 时,每个 PVC 对应一个 Access Point 的创建。EFS API 对 Access Point 的创建有速率限制,CSI controller 需要串行或小批量地调用 API。
1.3 Amazon S3:容量无限,但不是文件系统
S3 的扩展性和成本效益毋庸置疑,作为 Agent 数据的最终归档层没有问题。但 Agent 运行时需要的是 POSIX 文件语义:open、read、write、seek、rename、list directory 这些操作。S3 是对象存储,不支持原地修改、不支持 rename 原子性、不支持目录列举的一致性语义。
Mountpoint for Amazon S3 提供了 FUSE 挂载方案,但它明确声明只支持顺序写入新文件和读取已有文件,不支持随机写入和修改已有文件。对于需要反复修改 context 文件、append 日志、更新 checkpoint 的 Agent 工作流,这不是一个可行的运行时存储方案。
二、Curvine:为 Agent 规模化设计的分布式缓存文件系统
Curvine 是一个用 Rust 从头编写的高性能分布式缓存文件系统。名字来自"Curvature Engine"(曲率引擎),刘慈欣《三体》里的超光速推进装置,寓意对数据访问的极致加速。
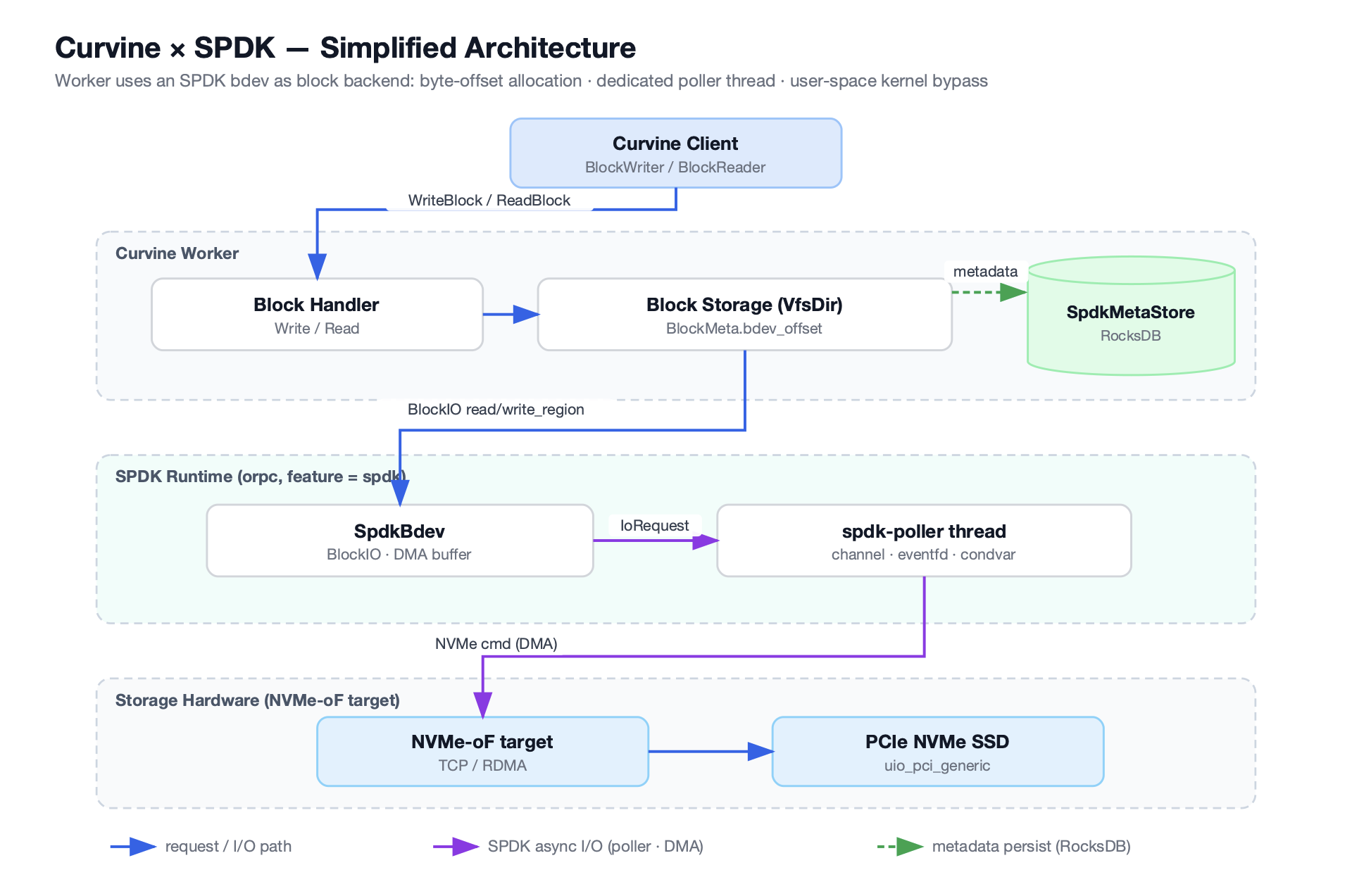
它的核心思路是:在云对象存储(如 S3)之上建立一层分布式文件系统缓存,向上提供完整的 POSIX 语义,向下以对象存储作为持久化层。对于 Kubernetes 工作负载,通过原生 CSI 驱动直接以 PVC 的方式挂载使用。
2.1 核心架构
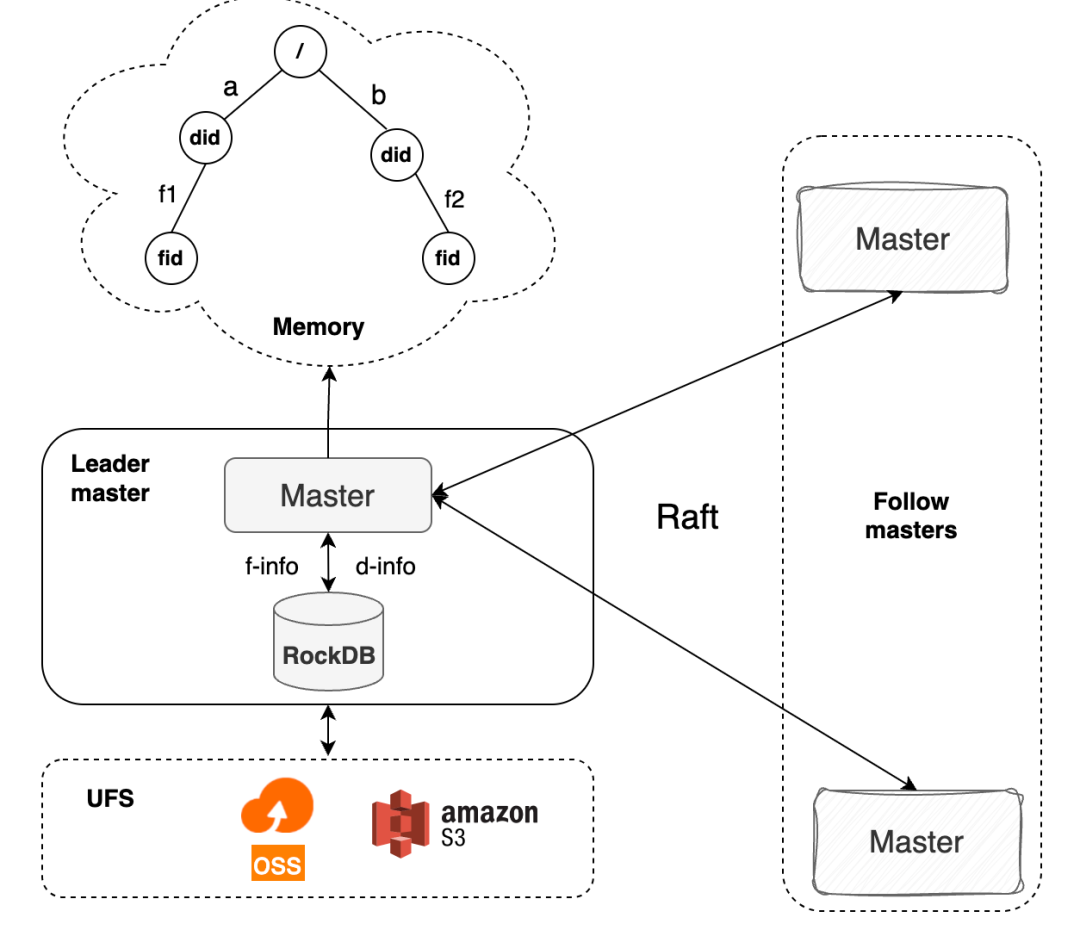
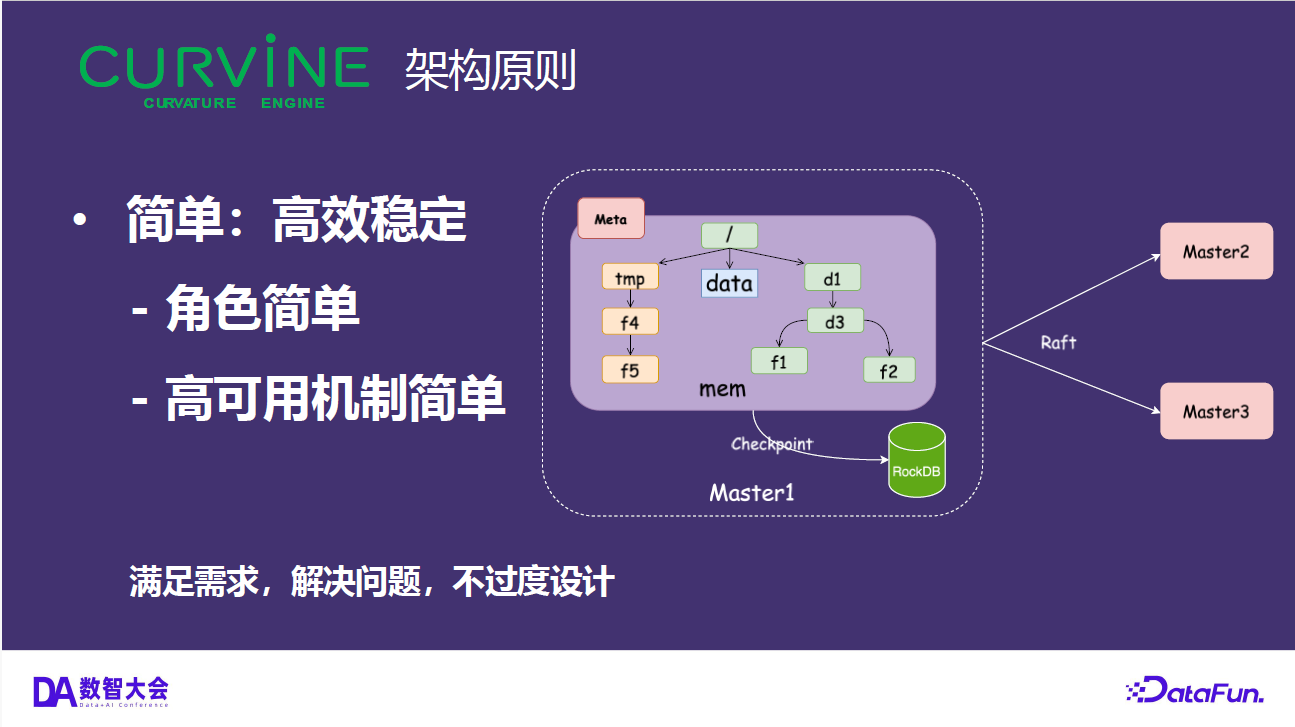
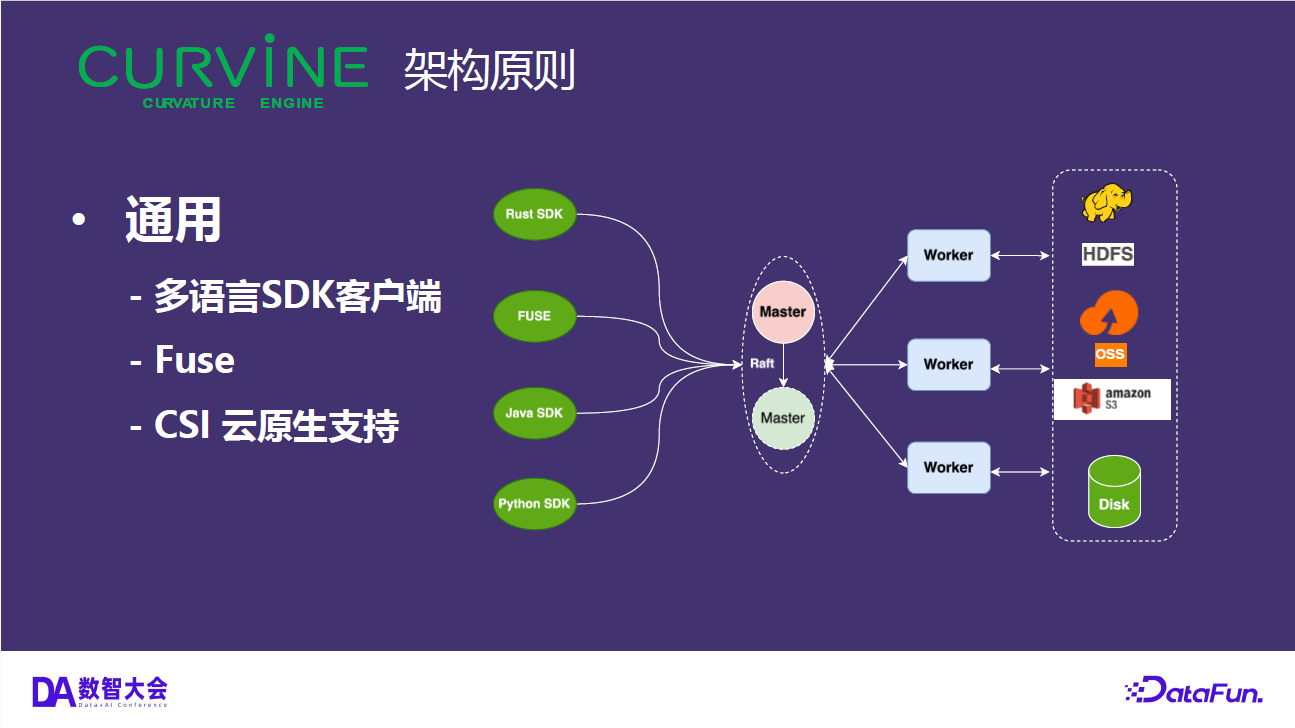
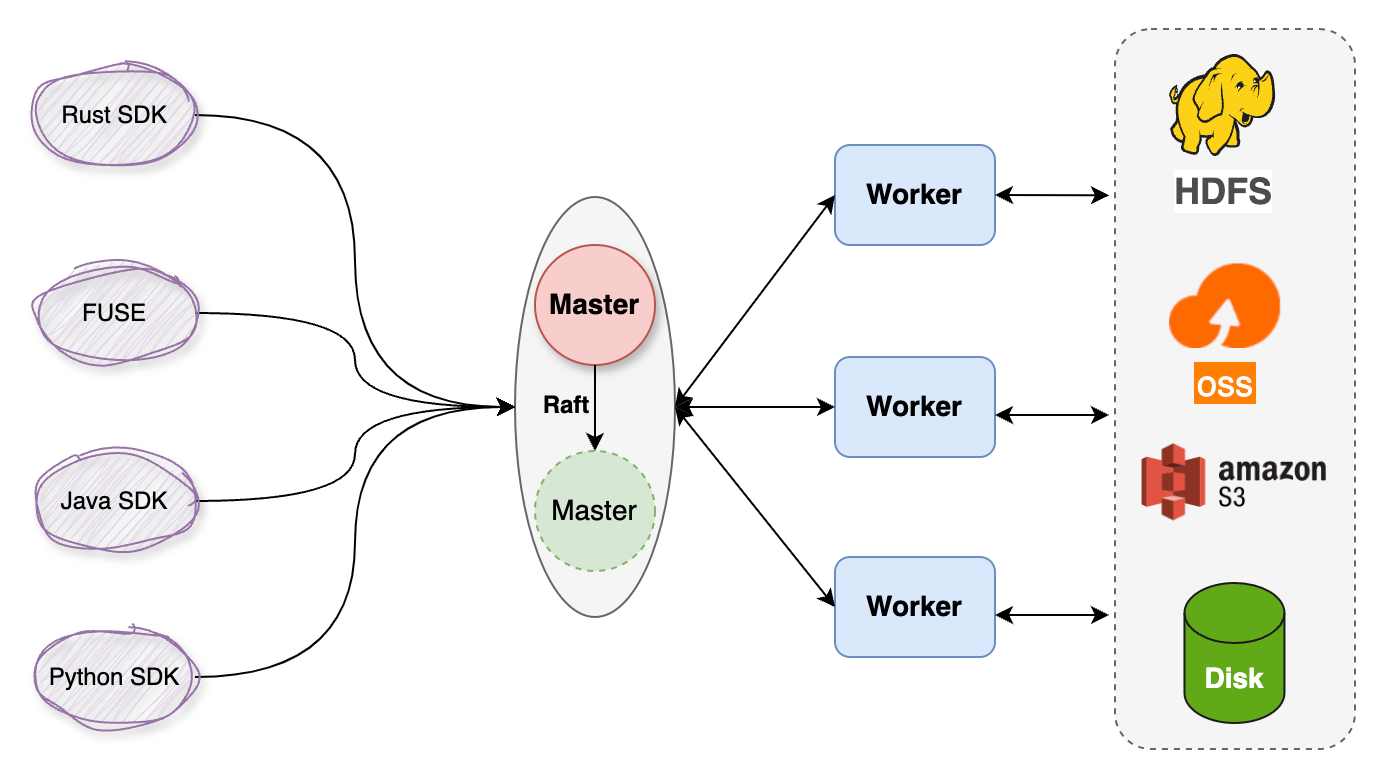
Curvine 采用 Master-Worker 架构:
- Master 节点:负责元数据管理、Worker 协调和负载均衡,使用 Raft 共识算法保证元数据的一致性和高可用
- Worker 节点:负责实际的数据缓存和服务,支持内存、SSD、HDD 多层缓存,热数据自动提升到更快的层级
- 客户端访问:通过 FUSE 挂载提供 POSIX 文件系统接口;同时兼容 S3 和 HDFS 协议,可以对接现有的 AI/大数据生态
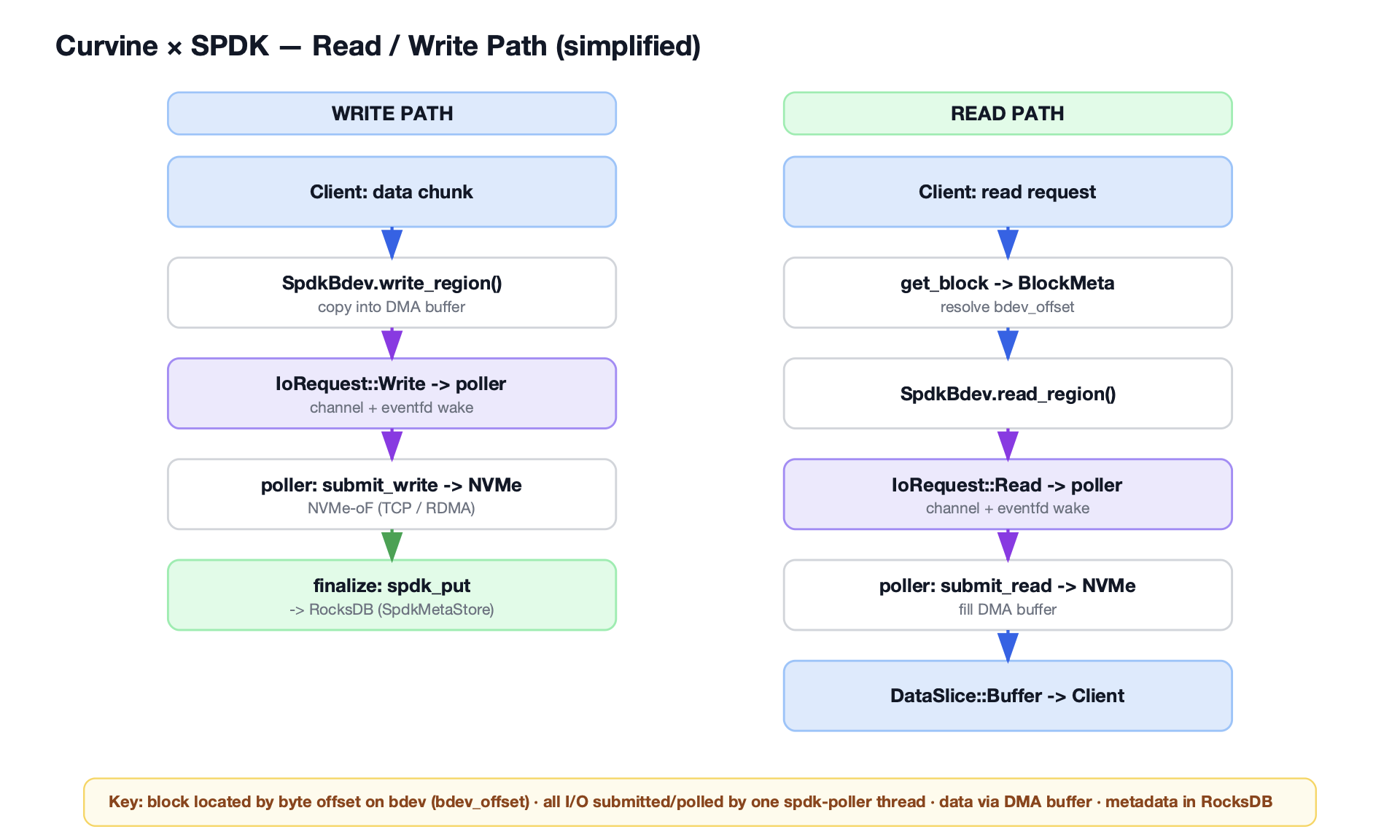
在 Kubernetes 环境中,Curvine 以 CSI 驱动的形式集成:CSI Controller 处理 PVC 的动态 provisioning,CSI Node DaemonSet 在每个节点上运行,负责 FUSE 挂载。这意味着存储的 provision 过程不需要调用外部云 API,只是在分布式文件系统上创建一个目录,可以在毫秒级完成。
2.2 为什么不是 JuiceFS
JuiceFS 是这个领域的先行者,用 Go 实现,架构上也是"元数据引擎 + 对象存储"的模式。Curvine 和它的核心差异在于:
- 性能层面:Curvine 用 Rust 实现核心读写路径,多次使用零拷贝技术,官方标称 100μs 级延迟和 100K+ 稳定 QPS。Rust 的异步 runtime(tokio)加上无 GC 的内存模型,在高并发小文件场景下理论上比 Go 的 runtime 有优势
- 元数据容量:Curvine 宣称单集群支持 50 亿小文件,万级 Agent 各自产生的小文件聚合起来是很大的 metadata 压力
- 元数据独立性:Curvine 的文件元数据路径与底层 S3 的对象路径一一对应,即使 Curvine 服务出现问题,S3 上的文件依然保持原始结构、可独立访问,恢复起来很方便。而 JuiceFS 会将文件拆分成 Block 存储,从 S3 的对象名无法识别出原始文件,元数据的可用性强依赖 JuiceFS 服务本身
- 缓存架构:Curvine 原生支持内存 → SSD → HDD 的多层自动分级,JuiceFS 也有本地缓存能力,但 Curvine 在缓存调度策略上做得更细粒度
- 定位差异:JuiceFS 更侧重通用场景和云厂商的深度集成,Curvine 明确将 AI 训练加速和 Agent 云原生存储作为一级用例
需要说明的是,这里并非要比较孰优孰劣。JuiceFS 与 Curvine 都是优秀的开源项目,在各自的设计目标下都做了大量工程优化,也都有活跃的社区。两者在架构取向上各有侧重,适用的场景也有所不同。具体选型应结合自身的工作负载特征、团队技术栈和运维偏好,通过实际测试来评估,本文不构成任何倾向性建议。
2.3 CSI 集成方式
在 EKS 上使用 Curvine 的 StorageClass 配置:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: curvine-sc
provisioner: curvine
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
parameters:
master-addrs: "curvine-master-0.curvine-master.curvine.svc.cluster.local:8995"
fs-path: "/k8s-volumes"
path-type: "DirectoryOrCreate"
io-threads: "4"
worker-threads: "8"
volumeBindingMode: Immediate 意味着 PVC 创建后立即绑定(不等 Pod 调度),path-type: DirectoryOrCreate 说明每个 PVC 对应的是 Curvine 文件系统上的一个目录,创建速度远快于需要调用云 API 的方案。
三、万级 Pod 基准测试:验证规模化可行性
我们在 Amazon EKS 上进行了一次规模验证测试,目标是回答一个问题:Curvine 能否在生产级 EKS 集群上,为 10,000 个独立的有状态 Pod 提供可靠的持久化存储?
3.1 测试环境
| 参数 | 配置 |
|---|---|
| Region | us-west-2 |
| Kubernetes 版本 | v1.31.14-eks |
| 计算节点 | 99 × r6g.4xlarge(Graviton ARM64,16 vCPU,128Gi RAM) |
| 节点供给 | Karpenter 自动扩缩 |
| 网络 | VPC-CNI |
3.2 工作负载配置
| 参数 | 数值 |
|---|---|
| 部署方式 | StatefulSet(podManagementPolicy: Parallel) |
| 副本数 | 10,000 |
| 每个 Pod 资源 | 131m CPU / 1190Mi Memory(Guaranteed QoS) |
| 每个 Pod 存储 | 独立 PVC,1Gi requested |
| 每节点 Pod 密度 | ~100 个 Agent Pod + 2 个系统 Pod |
| 节点资源利用率 | CPU 88% / Memory 98% |
3.3 Curvine 存储集群
| 组件 | 数量 | 说明 |
|---|---|---|
| Master | 1 | 元数据管理 |
| Worker | 3 | 数据缓存服务 |
| CSI Controller | 1 | 处理 PVC 动态 provisioning |
| CSI Node DaemonSet | 104 | 每个节点一个,负责 FUSE 挂载 |
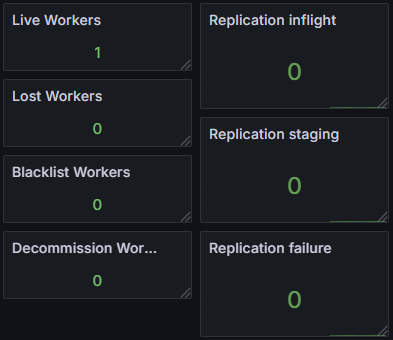
| 存储集群总计 | 109 个 Pod |
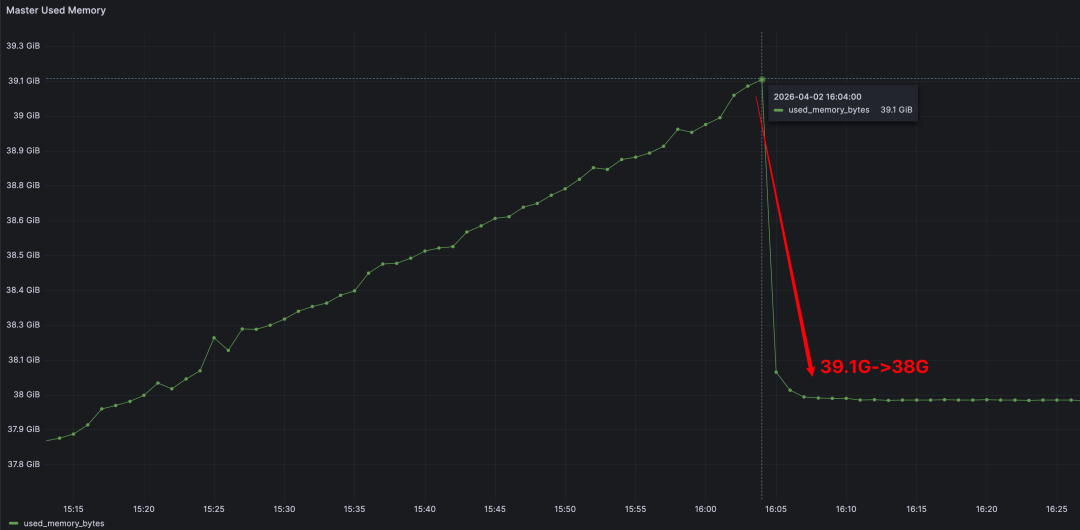
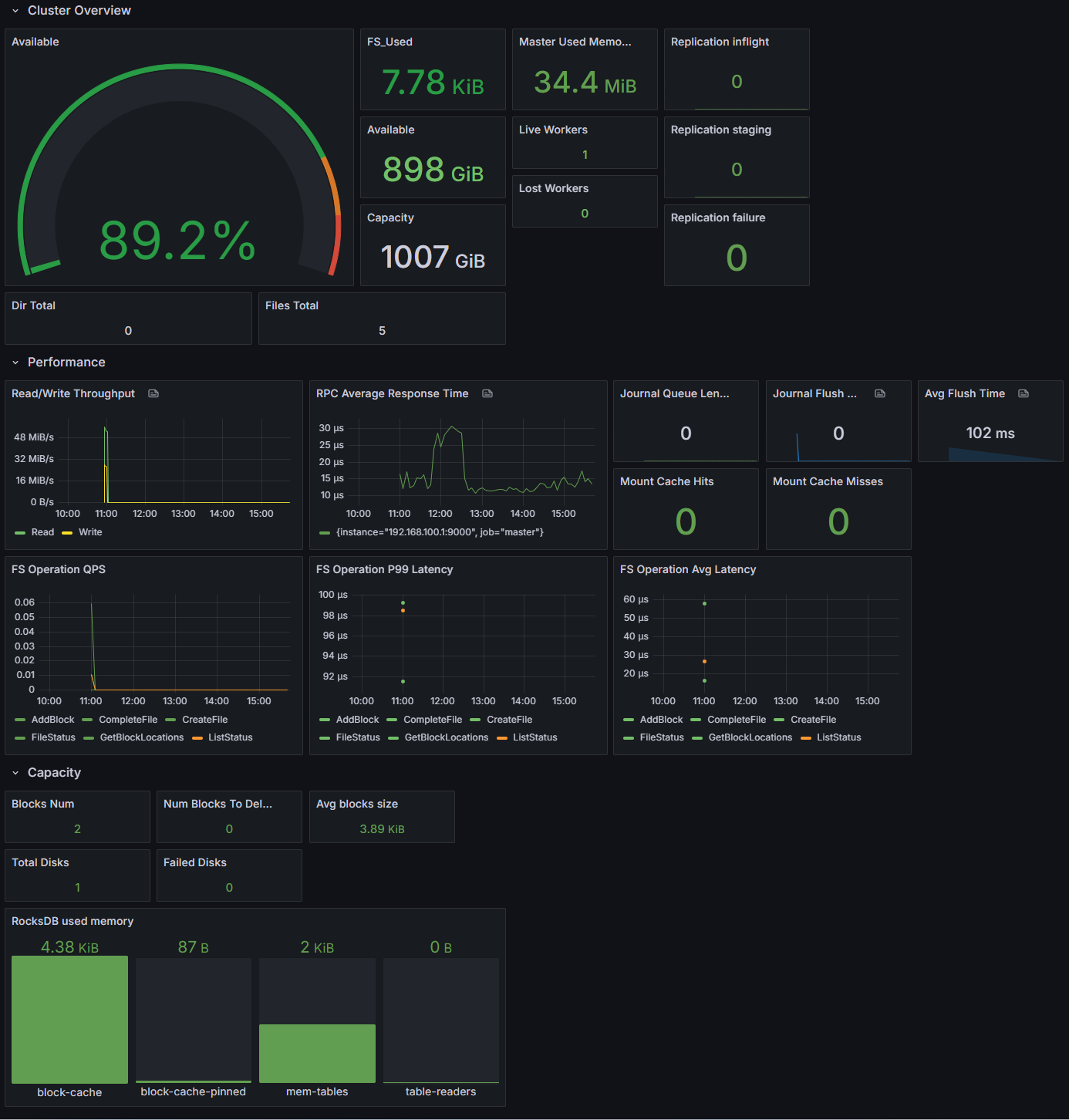
这里需要强调的数字是:支撑 10,000 个 PVC 的存储集群本身只有 1 Master + 3 Worker = 4 个核心 Pod。CSI Node DaemonSet 是轻量级的挂载代理,不消耗显著的计算资源。
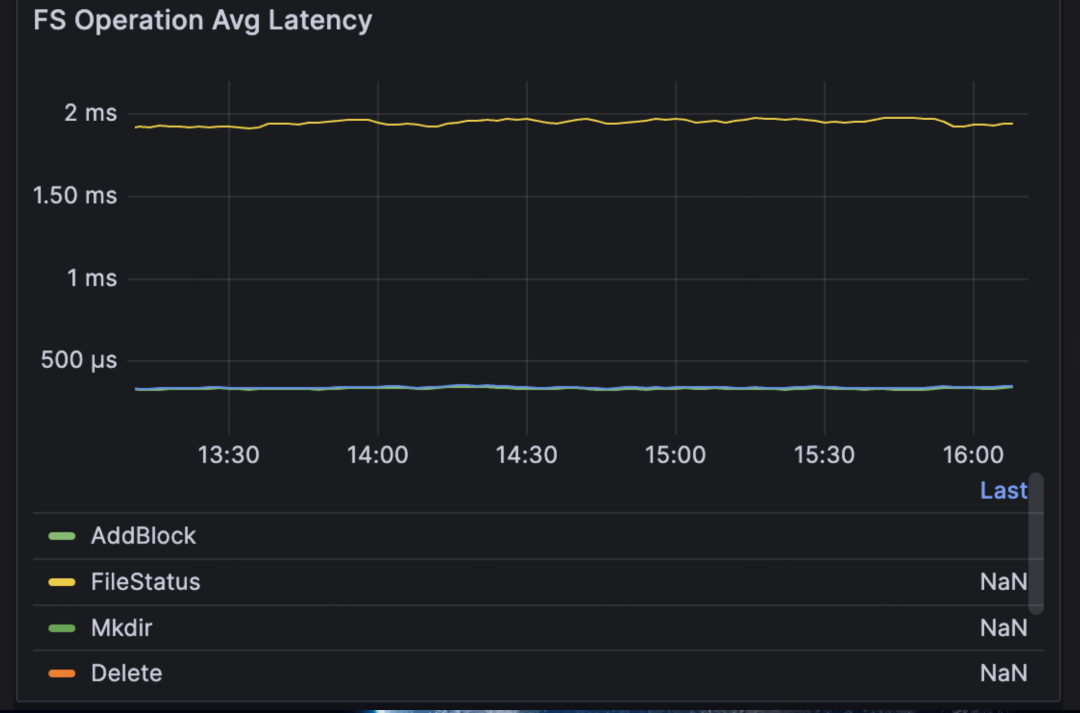
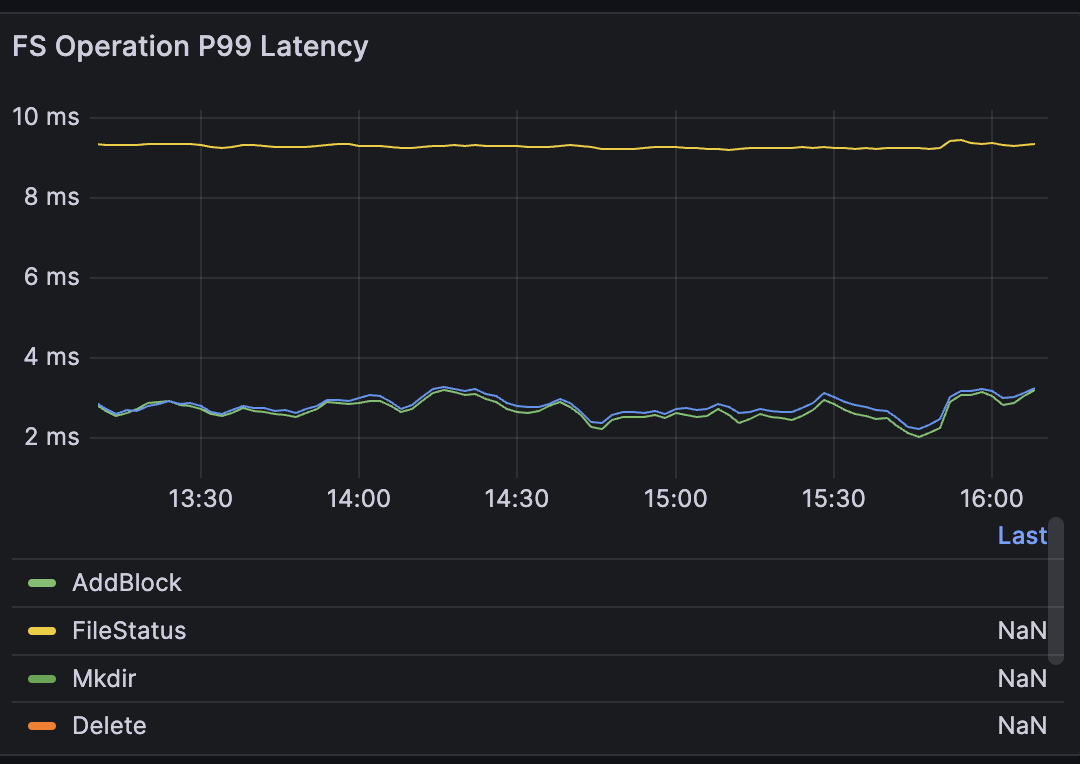
3.4 测试结果
供给成功率
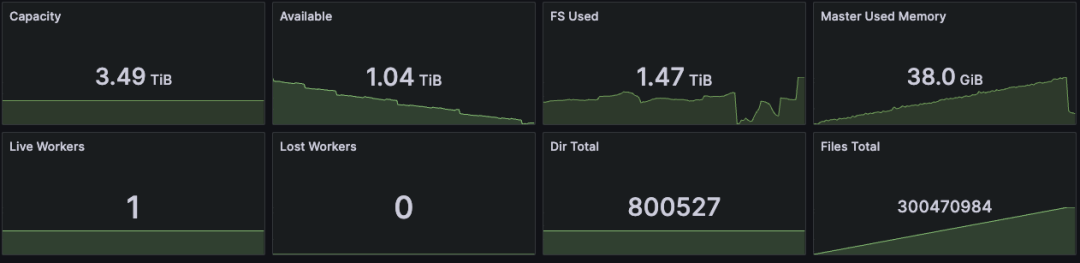
- 10,000 个 PVC:全部 Bound,零 Pending,零 Failed
- 10,000 个 Pod:全部 Running,零 CrashLoopBackOff,零存储相关错误
存储供给规格
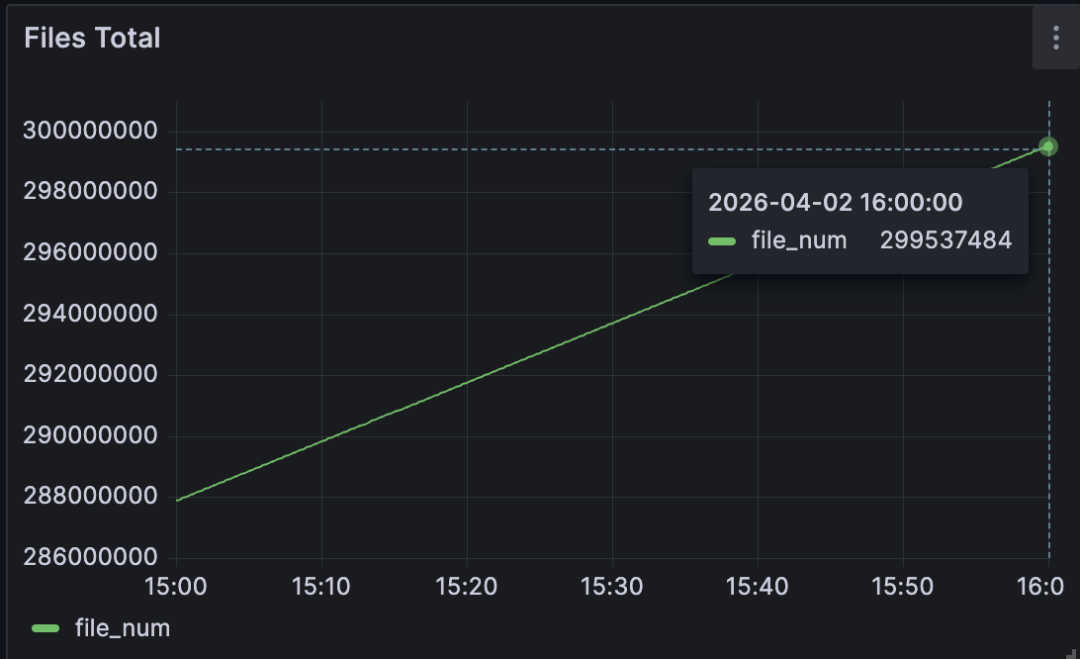
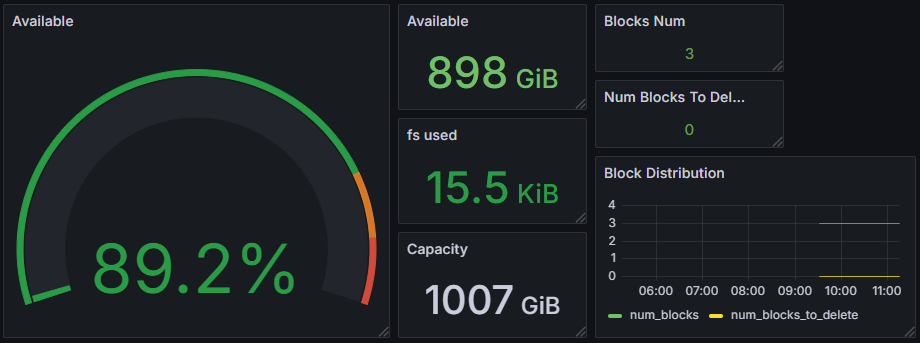
- 每个 PVC requested 1Gi,实际 provisioned ~30Gi(Curvine 的最小分配单元)
- 总 provisioned 存储容量:约 300TB
- 文件系统类型:curvinefs(FUSE 挂载)
数据持久性验证
- 在 pod-0、pod-5000、pod-9999 上分别写入数据并验证持久化
- Pod 重启后数据依然存在
- 跨节点调度后文件系统视图一致
Pod 分布均匀性
102 pods × 98 nodes = 9,996 pods
4 pods × 1 node = 4 pods
Total = 10,000 pods
每台 r6g.4xlarge 节点稳定承载 ~100 个 Agent Pod,CSI DaemonSet 与业务 Pod 共存无资源争抢。
3.5 每个 Pod 内看到的存储
Filesystem Size Used Available Use% Mounted on
curvinefs 29.8G 354.6M 29.5G 1% /usr/share/nginx/html
每个 Pod 拥有独立的文件系统视图,互相不可见,和 EBS 的逻辑隔离效果一致,但绕过了 EBS 的挂载数量限制。
3.6 关键结论
- Provision 不依赖云厂商控制平面 API:使用 EBS 时,创建 PVC 会触发 CSI 驱动调用 EBS 的 CreateVolume、AttachVolume 接口;使用 EFS 则会调用 CreateAccessPoint。这些云 API 都有速率限制,大规模并发创建时会排队、变慢。而 Curvine 创建一个 PVC 本质上只是在它自己的分布式文件系统里
mkdir一个目录,全程不调用任何云厂商 API,因此速度快、也不受云 API 限流的约束 - 存储集群的资源开销极小:4 个核心 Pod 服务万级 PVC,不需要为存储系统本身预留大量计算资源
- 单节点 Pod 密度不再受存储限制:100 个 Pod 共享同一个 FUSE 挂载点的不同路径,没有 EBS 那样的 28/128 上限
- 横向扩展路径清晰:如果需要更大规模或更高吞吐,增加 Worker 节点即可,对已有 PVC 无影响
四、试试看
如果你正在 EKS 上构建 AI Agent 平台,面对的是以下任一场景:
- 每个 Agent 实例需要独立的 POSIX 文件系统工作空间
- 总实例数在千级到万级,且需要快速弹性伸缩
- 单节点需要承载高密度的有状态 Pod(>28 个)
- 对小文件 I/O 延迟敏感(微秒级 vs 毫秒级)
那么 Curvine 值得纳入你的技术选型评估。
快速开始
- GitHub:github.com/CurvineIO/curvine
- 官方文档:curvineio.github.io
- EKS 集成:通过 Helm Chart 部署 Curvine 集群 + CSI 驱动,配置 StorageClass 后即可使用
建议的验证路径:从 100–500 个 Pod 开始,验证 provision 速度和 I/O 表现;如果满足预期,再逐步放量到千级甚至万级。存储集群本身从 1 Master + 1 Worker 起步即可,按需增加 Worker 节点扩展吞吐和缓存容量。
五、结语
AI Agent 带来的"海量小规模有状态实例"负载模式,对 Kubernetes 存储提出了全新挑战。EBS 的单实例挂载数限制、EFS 的 provision 瓶颈、S3 缺乏 POSIX 语义,各自在不同维度上难以满足需求。Curvine 作为面向这一场景设计的分布式缓存文件系统,在 EKS 上验证了 10,000 个独立 PVC 可以被可靠供给和服务,且存储集群本身资源开销极小——为 Agent 平台的规模化扩展提供了切实可行的存储底座。